Excel 스프레드시트에는 데이터 입력을 단순화 및/또는 표준화하기 위한 셀 드롭다운이 포함되는 경우가 많습니다. 이러한 드롭다운은 데이터 유효성 검사 기능을 사용하여 생성되어 허용되는 항목 목록을 지정합니다.
간단한 드롭다운 목록을 설정하려면 데이터를 입력할 셀을 선택한 다음 데이터 유효성 검사(Data Validation) ( 데이터(Data) 탭에서) 를 클릭하고 데이터 유효성 검사(Data Validation) 를 선택 하고 허용(Allow) 아래 에서 목록(List) 을 선택한 다음(쉼표로 구분된) 목록 항목을 입력합니다. ) 소스(Source) : 필드(그림 1 참조).
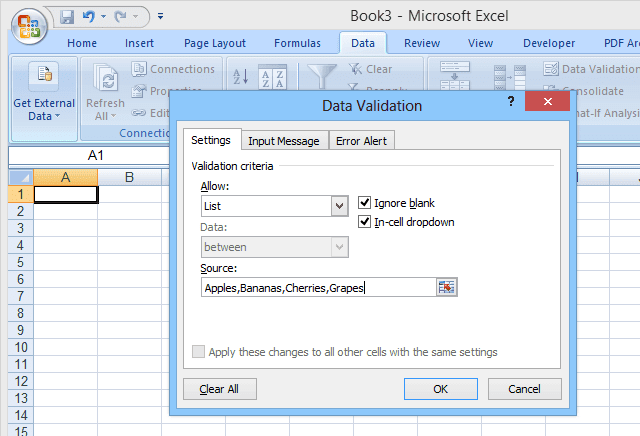
이 유형의 기본 드롭다운에서 허용 가능한 항목 목록은 데이터 유효성 검사 자체 내에서 지정됩니다. 따라서 목록을 변경하려면 사용자가 데이터 유효성 검사를 열고 편집해야 합니다. 그러나 경험이 없는 사용자나 선택 목록이 긴 경우에는 어려울 수 있습니다.
또 다른 옵션은 스프레드시트 내의 명명된 범위 에 목록을 배치한 다음 데이터 유효성 검사의 (named range within the spreadsheet)소스(Source) : 필드에 해당 범위 이름(등호로 시작)을 지정하는 것입니다 ( 그림 2(Figure 2) 참조).

이 두 번째 방법을 사용하면 목록에서 선택 항목을 더 쉽게 편집할 수 있지만 항목을 추가하거나 제거하면 문제가 될 수 있습니다. 명명된 범위( 이 예에서 FruitChoices )는 고정된 범위의 셀(표시된 대로 $H$3:$H$10)을 참조하므로 H11 이하의 셀에 더 많은 선택 항목이 추가되면 드롭다운에 표시되지 않습니다. (이러한 세포는 FruitChoices 범위의 일부가 아니기 때문에).
마찬가지로 예를 들어 배(Pears) 와 딸기(Strawberries) 항목이 지워지면 드롭다운에 더 이상 나타나지 않지만 드롭다운은 여전히 빈 셀 H9 및 H10 .
이러한 이유로 일반 명명된 범위를 드롭다운의 목록 소스로 사용할 때 항목이 목록에서 추가되거나 삭제되는 경우 명명된 범위 자체를 편집하여 더 많거나 적은 셀을 포함해야 합니다.
이 문제에 대한 해결책은 동적(dynamic) 범위 이름을 드롭다운 선택의 소스로 사용하는 것입니다. 동적 범위 이름은 항목이 추가되거나 제거될 때 데이터 블록의 크기와 정확히 일치하도록 자동으로 확장(또는 축소)되는 이름입니다. 이렇게 하려면 고정된 셀 주소 범위가 아닌 수식 을 사용하여 명명된 범위를 정의합니다.(formula)
Excel 에서 동적 범위(Dynamic Range) 를 설정하는 방법
일반(정적) 범위 이름은 지정된 셀 범위를 나타냅니다(이 예에서는 $H$3:$H$10, 아래 참조).

그러나 동적 범위는 공식을 사용하여 정의됩니다(아래 참조, 동적 범위 이름을 사용하는 별도의 스프레드시트에서 가져옴).

시작하기 전에 Excel 예제 파일 을 다운로드해야 합니다 (정렬 매크로가 비활성화됨).
이 공식을 자세히 살펴보겠습니다. 과일에 대한 선택은 제목( FRUITS(FRUITS) ) 바로 아래에 있는 셀 블록에 있습니다 . 이 제목에는 다음과 같은 이름도 할당 됩니다(FruitsHeading) .

과일(Fruits) 선택에 대한 동적 범위를 정의하는 데 사용되는 전체 공식 은 다음과 같습니다.
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(OFFSET(FruitsHeading,1,0,20,1)),0,0),0)-1,20),1)
FruitsHeading 은 목록의 첫 번째 항목 위의 한 행에 있는 제목을 나타냅니다. 숫자 20(수식에서 두 번 사용됨)은 목록의 최대 크기(행 수)입니다(원하는 대로 조정할 수 있음).
이 예에서는 목록에 8개의 항목만 있지만 추가 항목을 추가할 수 있는 빈 셀도 이 아래에 있습니다. 숫자 20은 실제 항목 수가 아니라 항목을 만들 수 있는 전체 블록을 나타냅니다.
이제 공식을 조각으로 분해(각 조각의 색상 코딩)하여 작동 방식을 이해해 보겠습니다.
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(OFFSET(FruitsHeading,1,0,20,1)),0,0),0)-1,20),1)
"가장 안쪽" 부분은 OFFSET(FruitsHeading,1,0,20,1) 입니다. 이것은 선택 항목을 입력할 수 있는 20개의 셀 블록( FruitsHeading 셀 아래)을 참조합니다. 이 OFFSET 함수는 기본적으로 다음과 같이 말합니다. FruitsHeading 셀에서 시작하여 1행 아래로 0열 이상으로 이동한 다음 길이 20행, 너비 1열인 영역을 선택합니다. 그러면 과일(Fruits) 선택이 입력되는 20행 블록이 제공됩니다.
수식의 다음 부분은 ISBLANK 함수입니다.
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(the above),0,0),0)-1,20),1)
여기에서 OFFSET 기능(위에 설명됨)은 "위"로 대체되었습니다(읽기 쉽도록). 그러나 ISBLANK 함수는 (ISBLANK)OFFSET 함수가 정의 하는 20행 셀 범위에서 작동합니다.
그런 다음 ISBLANK 는 20개의 (ISBLANK)TRUE 및 FALSE 값 집합을 만들어 OFFSET 함수 에서 참조하는 20행 범위의 각 개별 셀 이 비어 있는지(비어 있는지) 여부를 나타냅니다. 이 예에서 처음 8개 셀이 비어 있지 않고 마지막 12개 값이 TRUE 이므로 집합의 처음 8개 값은 (TRUE)FALSE 가 됩니다 .
공식의 다음 부분은 INDEX 함수입니다.
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(the above,0,0),0)-1,20),1)
다시 "위"는 위에서 설명한 ISBLANK 및 OFFSET 기능을 나타냅니다. INDEX 함수 는 ISBLANK 함수에 의해 생성된 20개의 (ISBLANK)TRUE / FALSE 값 을 포함하는 배열을 반환합니다 .
INDEX 는 일반적으로 특정 행과 열(해당 블록 내)을 지정하여 데이터 블록에서 특정 값(또는 값 범위)을 선택하는 데 사용됩니다. 그러나 행 및 열 입력을 0으로 설정하면(여기서 수행됨) INDEX 가 전체 데이터 블록을 포함하는 배열을 반환합니다.
수식의 다음 부분은 MATCH 함수입니다.
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,the above,0)-1,20),1)
MATCH 함수는 (MATCH)INDEX 함수 에서 반환된 배열 내에서 첫 번째 TRUE 값 의 위치를 반환 합니다. 목록의 처음 8개 항목은 비어 있지 않으므로 배열의 처음 8개 값은 FALSE 가 되고 9번째 값은 TRUE 가 됩니다 (범위의 9 번째 행이 비어 있으므로).
따라서 MATCH 함수는 9 값을 반환합니다 . 그러나 이 경우 목록에 몇 개의 항목이 있는지 알고 싶으므로 공식은 MATCH 값(마지막 항목의 위치를 제공함)에서 1을 뺍니다. 따라서 궁극적으로 MATCH ( TRUE ,위,0)-1은 8 값을 반환합니다 .
수식의 다음 부분은 IFERROR 함수입니다.
=OFFSET(FruitsHeading,1,0,IFERROR(the above,20),1)
IFERROR 함수는 지정된 첫 번째 값으로 인해 오류가 발생하는 경우 대체 값을 반환합니다 . 전체 셀 블록(20개 행 모두)이 항목으로 채워지면 MATCH 함수가 오류를 반환하므로 이 함수가 포함됩니다.
이는 MATCH 함수에 (MATCH)ISBLANK 함수 의 값 배열에서 첫 번째 TRUE 값 을 찾도록 지시하기 때문입니다. 그러나 셀(NONE) 중 아무 것도 비어 있지 않으면 전체 배열이 FALSE 값으로 채워집니다. MATCH 가 검색 중인 배열에서 대상 값( TRUE )을 찾을 수 없으면 오류를 반환합니다.
따라서 전체 목록이 가득 차면(따라서 MATCH 가 오류를 반환함) IFERROR 함수는 대신 값 20을 반환합니다(목록에 20개의 항목이 있어야 함을 알고 있음).
마지막으로 OFFSET(FruitsHeading,1,0,the above,1) 은 우리가 실제로 찾고 있는 범위를 반환합니다. FruitsHeading 셀에서 시작하여 1행 아래로 0열 이상으로 이동한 다음 목록에 항목이 있습니다(1개 열 너비). 따라서 전체 수식은 실제 항목만 포함하는 범위를 반환합니다(첫 번째 빈 셀까지).
이 공식을 사용하여 드롭다운의 소스인 범위를 정의하면 목록을 자유롭게 편집할 수 있으며(나머지 항목이 맨 위 셀에서 시작하고 연속되어 있는 한 항목 추가 또는 제거) 드롭다운은 항상 현재를 반영합니다. 목록( 그림 6(Figure 6) 참조 ).

여기에 사용 된 예제 파일(동적 목록) 이 포함되어 있으며 이 웹사이트에서 다운로드할 수 있습니다. 그러나 WordPress 는 매크로가 포함된 (WordPress)Excel 책을 좋아하지 않기 때문에 매크로가 작동하지 않습니다.
목록 블록의 행 수를 지정하는 대신 목록 블록에 자체 범위 이름을 할당한 다음 수정된 수식에서 사용할 수 있습니다. 예제 파일에서 두 번째 목록( Names )은 이 방법을 사용합니다. 여기에서 전체 목록 블록(예제 파일의 "NAMES" 제목 아래, 40개 행)에는 NameBlock 의 범위 이름이 할당됩니다 . NamesList 를 정의하기 위한 대체 공식 은 다음과 같습니다.
=OFFSET(NamesHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(NamesBlock),0,0),0)-1,ROWS(NamesBlock)),1)
여기서 NamesBlock 은 이전 수식의 (NamesBlock)OFFSET ( FruitsHeading,1,0,20,1 )을 대체 하고 ROWS(NamesBlock) 는 20(행 수)을 대체합니다.
따라서 쉽게 편집할 수 있는 드롭다운 목록(경험이 없는 다른 사용자 포함)의 경우 동적 범위 이름을 사용해 보십시오! 이 문서는 드롭다운 목록에 중점을 두었지만 크기가 다양할 수 있는 범위 또는 목록을 참조해야 하는 모든 곳에서 동적 범위 이름을 사용할 수 있습니다. 즐기다!
Use Dynamic Range Names in Excel for Flexible Dropdowns
Excel spreаdsheetѕ often include cell dropdowns to simplify and/or standardize data entry. Τhese dropdowns are creаted using the data validation feature to specify a list of аllowable entriеs.
To set up a simple dropdown list, select the cell where data will be entered, then click Data Validation (on the Data tab), select Data Validation, choose List (under Allow:), and then enter the list items (separated by commas) in the Source: field (see Figure 1).
In this type of basic dropdown, the list of allowable entries is specified within the data validation itself; therefore, to make changes to the list, the user must open and edit the data validation. This may be difficult, however, for inexperienced users, or in cases where the list of choices is lengthy.
Another option is to place the list in a named range within the spreadsheet, and then specify that range name (prefaced with an equal sign) in the Source: field of the data validation (as shown in Figure 2).
This second method makes it easier to edit the choices in the list, but adding or removing items can be problematic. Since the named range (FruitChoices, in our example) refers to a fixed range of cells ($H$3:$H$10 as shown), if more choices are added to the cells H11 or below, they will not show up in the dropdown (since those cells are not part of the FruitChoices range).
Likewise if, for example, the Pears and Strawberries entries are erased, they will no longer appear in the dropdown, but instead the dropdown will include two “empty” choices since the dropdown still references the entire FruitChoices range, including the empty cells H9 and H10.
For these reasons, when using a normal named range as the list source for a dropdown, the named range itself must be edited to include more or fewer cells if entries are added or deleted from the list.
A solution to this problem is to use a dynamic range name as the source for the dropdown choices. A dynamic range name is one that automatically expands (or contracts) to exactly match the size of a block of data as entries are added or removed. To do this, you use a formula, rather than a fixed range of cell addresses, to define the named range.
How to Setup a Dynamic Range in Excel
A normal (static) range name refers to a specified range of cells ($H$3:$H$10 in our example, see below):
But a dynamic range is defined using a formula (see below, taken from a separate spreadsheet which uses dynamic range names):
Before we get started, make sure you download our Excel example file (sort macros have been disabled).
Let’s examine this formula in detail. The choices for Fruits are in a block of cells directly below a heading (FRUITS). That heading is also assigned a name: FruitsHeading:
The entire formula used to define the dynamic range for the Fruits choices is:
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(OFFSET(FruitsHeading,1,0,20,1)),0,0),0)-1,20),1)
FruitsHeading refers to the heading that is one row above the first entry in the list. The number 20 (used two times in the formula) is the maximum size (number of rows) for the list (this can be adjusted as desired).
Note that in this example, there are only 8 entries in the list, but there are also empty cells below these where additional entries could be added. The number 20 refers to the entire block where entries can be made, not to the actual number of entries.
Now let’s break down the formula into pieces (color-coding each piece), to understand how it works:
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(OFFSET(FruitsHeading,1,0,20,1)),0,0),0)-1,20),1)
The “innermost” piece is OFFSET(FruitsHeading,1,0,20,1). This references the block of 20 cells (underneath the FruitsHeading cell) where choices may be entered. This OFFSET function basically says: Start at the FruitsHeading cell, go down 1 row and over 0 columns, then select an area that is 20 rows long and 1 column wide. So that gives us the 20-row block where the Fruits choices are entered.
The next piece of the formula is the ISBLANK function:
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(the above),0,0),0)-1,20),1)
Here, the OFFSET function (explained above) has been replaced with “the above” (to make things easier to read). But the ISBLANK function is operating on the 20-row range of cells that the OFFSET function defines.
ISBLANK then creates a set of 20 TRUE and FALSE values, indicating whether each of the individual cells in the 20-row range referenced by the OFFSET function is blank (empty) or not. In this example, the first 8 values in the set will be FALSE since the first 8 cells are not empty and the last 12 values will be TRUE.
The next piece of the formula is the INDEX function:
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(the above,0,0),0)-1,20),1)
Again, “the above” refers to the ISBLANK and OFFSET functions described above. The INDEX function returns an array containing the 20 TRUE / FALSE values created by the ISBLANK function.
INDEX is normally used to pick a certain value (or range of values) out of a block of data, by specifying a certain row and column (within that block). But setting the row and column inputs to zero (as is done here) causes INDEX to return an array containing the entire block of data.
The next piece of the formula is the MATCH function:
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,the above,0)-1,20),1)
The MATCH function returns the position of the first TRUE value, within the array that’s returned by the INDEX function. Since the first 8 entries in the list are not blank, the first 8 values in the array will be FALSE, and the ninth value will be TRUE (since the 9th row in the range is empty).
So the MATCH function will return the value of 9. In this case, however, we really want to know how many entries are in the list, so the formula subtracts 1 from the MATCH value (which gives the position of the last entry). So ultimately, MATCH(TRUE,the above,0)-1 returns the value of 8.
The next piece of the formula is the IFERROR function:
=OFFSET(FruitsHeading,1,0,IFERROR(the above,20),1)
The IFERROR function returns an alternate value, if the first value specified results in an error. This function is included since, if the entire block of cells (all 20 rows) are filled with entries, the MATCH function will return an error.
This is because we’re telling the MATCH function to look for the first TRUE value (in the array of values from the ISBLANK function), but if NONE of the cells are empty, then the entire array will be filled with FALSE values. If MATCH cannot find the target value (TRUE) in array it is searching, it returns an error.
So, if the entire list is full (and therefore, MATCH returns an error), the IFERROR function will instead return the value of 20 (knowing that there must be 20 entries in the list).
Finally, OFFSET(FruitsHeading,1,0,the above,1) returns the range we are actually looking for: Start at the FruitsHeading cell, go down 1 row and over 0 columns, then select an area that is however many rows long as there are entries in the list (and 1 column wide). So the entire formula together will return the range that contains only the actual entries (down to the first empty cell).
Using this formula to define the range that is the source for the dropdown means you can freely edit the list (adding or removing entries, as long as the remaining entries start at the top cell and are contiguous) and the dropdown will always reflect the current list (see Figure 6).
The example file (Dynamic Lists) that’s been used here is included and is downloadable from this website. The macros don’t work, however, because WordPress doesn’t like Excel books with macros in them.
As an alternative to specifying the number of rows in the list block, the list block can be assigned its own range name, which can then be used in a modified formula. In the example file, a second list (Names) uses this method. Here, the entire list block (underneath the “NAMES” heading, 40 rows in the example file) is assigned the range name of NameBlock. The alternate formula for defining the NamesList is then:
=OFFSET(NamesHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(NamesBlock),0,0),0)-1,ROWS(NamesBlock)),1)
where NamesBlock replaces OFFSET(FruitsHeading,1,0,20,1) and ROWS(NamesBlock) replaces the 20 (number of rows) in the earlier formula.
So, for dropdown lists which can be easily edited (including by other users who may be inexperienced), try using dynamic range names! And note that, although this article has been focused on dropdown lists, dynamic range names can be used anywhere you need to reference a range or list that can vary in size. Enjoy!
