텍스트로 변환하고 싶은 PDF 문서(PDF document) 나 이미지가 있습니까 ? 최근 누군가가 메일로 문서를 보내 수정하고 다시 보내야 하는 문서를 보냈습니다. 그 사람은 디지털 사본을 찾을 수 없었습니다. 그래서 저는 그 모든 텍스트를 디지털 형식으로 변환하는 임무를 받았습니다.
모든 것을 다시 입력하는 데 몇 시간을 소비할 방법이 없었습니다. 그래서 결국 문서의 멋진 고품질 사진을 찍은 다음 여러 온라인 OCR 서비스를 검색하여 어떤 서비스가 가장 좋은지 확인했습니다. 결과.
이 기사에서는 내가 즐겨 사용하는 무료 OCR 사이트 몇 개를 살펴보겠습니다. (OCR)이러한 사이트의 대부분은 기본 무료 서비스를 제공하고 더 큰 이미지, 다중 페이지 PDF(PDF) 문서, 다양한 입력 언어 등과 같은 추가 기능을 원하는 경우 유료 옵션을 제공한다는 점은 주목할 가치가 있습니다 .
또한 이러한 서비스의 대부분은 원본 문서의 형식과 일치하지 않을 수 있다는 점을 미리 알아두는 것이 좋습니다. 이것들은 주로 텍스트를 추출하는 데 사용됩니다. 모든 것이 특정 레이아웃이나 형식 이어야 하는 경우 (layout or format)OCR 에서 모든 텍스트를 가져온 후에 수동으로 수행해야 합니다 .
또한 텍스트를 가져오기 위한 최상의 결과는 200~ 400DPI 해상도(DPI resolution) 의 문서에서 나옵니다 . DPI 이미지(DPI image) 가 낮으면 결과가 좋지 않습니다.
마지막으로 테스트한 사이트 중 작동(t work) 하지 않는 사이트가 많이 있었습니다 . Google에서 무료 온라인 OCR 을 사용하면 여러 사이트를 볼 수 있지만 상위 10개 결과에 있는 사이트 중 일부는 변환을 완료하지도 않았습니다. 일부는 시간이 초과되고 다른 일부는 오류가 발생하고 일부는 "변환 중" 페이지에서 멈췄습니다. 그래서 저는 해당 사이트를 언급하는 것을 귀찮게 생각하지 않았습니다.
각 사이트에 대해 두 개의 문서를 테스트하여 출력이 얼마나 좋은지 확인했습니다. 테스트를 위해 iPhone 5S 를 사용하여 두 문서의 사진을 찍은 다음 변환을 위해 웹사이트에 직접 업로드했습니다.
테스트에 사용한 이미지가 어떻게 생겼는지 알고 싶다면 여기에 첨부했습니다. Test1 및 Test2 . 이것은 전화기에서 찍은 이미지의 전체 해상도 버전이 아닙니다. 사이트에 업로드할 때 전체 해상도 이미지 를 사용했습니다.(resolution image)
온라인OCR
OnlineOCR.net 은 내 테스트에서 매우 좋은 결과를 제공한 깨끗하고 간단한 사이트입니다. 내가 그것에 대해 가장 좋아하는 것은 그것이 일반적으로 이러한 종류의 틈새 서비스(niche service) 사이트의 경우인 모든 곳에 광고가 없다는 것입니다.

시작하려면 파일을 선택 하고 업로드가 완료 될 때까지 기다리세요 . (file and wait till)이 사이트의 최대 업로드 크기는 100MB입니다. 무료 계정에 등록하면 더 큰 업로드 크기, 여러 페이지 PDF(PDFs) , 다양한 입력 언어, 시간당 더 많은 전환 등과 같은 몇 가지 추가 기능을 얻을 수 있습니다.
그런 다음 입력 언어(input language) 를 선택한 다음 출력 형식(output format) 을 선택합니다 . Word , Excel 또는 일반 텍스트(Plain Text) 중에서 선택할 수 있습니다 . 변환 버튼을 (Convert)클릭(Click) 하면 다운로드 링크(download link) 와 함께 상자 하단에 텍스트가 표시됩니다 .
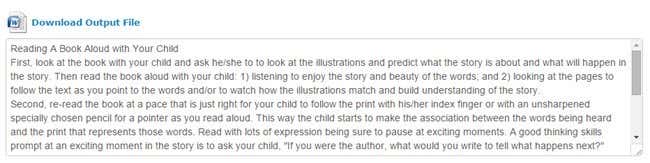
텍스트만 원하는 경우 상자에서 복사하여 붙여넣으면 됩니다. (copy and paste)그러나 Word 문서(Word document) 는 원본 문서의 레이아웃을 유지하는 데 놀라울 정도로 훌륭하기 때문에 다운로드하는 것이 좋습니다 .
예를 들어, 두 번째 테스트를 위해 Word 문서(Word document) 를 열었을 때 문서 에 이미지와 같이 3개의 열이 있는 표가 포함되어 있다는 사실에 놀랐습니다.

모든 사이트 중에서 이 사이트가 단연 최고였습니다. 많은 전환이 필요한 경우 등록할 가치가 있습니다.
완성도를 위해 각 서비스에서 생성한 출력 파일도 링크하여 직접 결과를 확인할 수 있도록 하겠습니다. 다음은 OnlineOCR : Test1 Doc 및 Test2 Doc(Test1 Doc and Test2 Doc) 의 결과 입니다.
컴퓨터에서 이러한 Word 문서를 열면 (Word)인터넷에서 가져온 것이며 편집(Internet and editing) 이 비활성화 되었다는 메시지가 Word 에 표시됩니다. (Word)Word 는 (Word doesn)인터넷(Internet) 의 문서를 신뢰 하지 않으며 문서를 보기만 하려는 경우 편집을 활성화할 필요가 없기 때문에 완벽 합니다.
i2OCR
꽤 좋은 결과를 준 또 다른 사이트는 i2OCR 입니다. 프로세스는 매우 유사합니다. 언어, 파일을 선택한 다음 텍스트 추출(Extract Text) 을 누릅니다 .

이 사이트는 시간이 조금 더 걸리기 때문에 여기에서 1~2분 정도 기다려야 합니다. 또한 2단계(Step 2) 에서 미리보기에서 이미지가 오른쪽 위로 표시되는지 확인하세요. 어떤 이유로 내 iPhone의 이미지가 내 컴퓨터에서는 세로 모드(portrait mode) 로 표시 되지만 이 사이트에 업로드할 때는 가로 모드로 표시되었습니다.
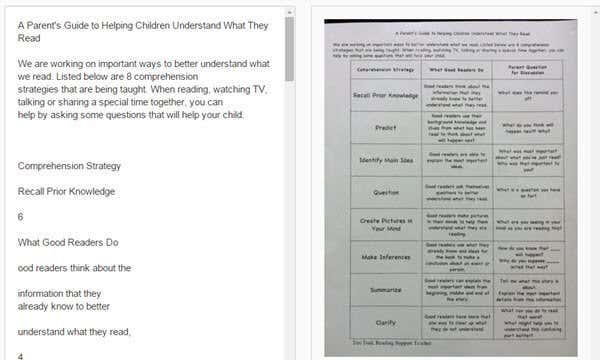
사진 편집 앱에서 이미지를 수동으로 열고 90도 회전한 다음 다시 세로 방향으로 회전한 다음 다시 저장해야 했습니다. 완료되면 아래로 스크롤하면 (Once)다운로드 버튼(download button) 과 함께 텍스트 미리보기가 표시 됩니다.
이 사이트는 첫 번째 테스트의 출력에서는 꽤 좋은 결과를 얻었지만 열 레이아웃(column layout) 이 있는 두 번째 테스트에서는 잘 되지 않았습니다 . 다음은 i2OCR의 결과입니다. Test1 Doc 및 Test2 Doc(Test1 Doc and Test2 Doc) .
무료OCR
Free-OCR.com 은 이미지를 (Free-OCR.com)일반 텍스트(plain text) 로 변환합니다 . Word 형식(Word format) 으로 내보내는 옵션이 없습니다 . 파일을 선택하고 언어를 선택한 다음 시작(Start) 을 클릭 합니다.
사이트는 빠르며 출력을 상당히 빨리 얻을 수 있습니다. 링크를 클릭 하면 (Just click)텍스트 파일(text file) 을 컴퓨터에 다운로드할 수 있습니다.

아래에 언급된 NewOCR 과 마찬가지로 이 사이트는 문서의 모든 T를 대문자로 표시합니다. 왜 그렇게 하는지는 모르겠지만 이상한 이유로 이 사이트와 NewOCR(site and NewOCR) 모두에서 이 작업을 수행했습니다. 변경하는 것은 큰 문제가 아니지만 실제로 하지 않아도 되는 지루한 과정입니다.
다음은 FreeOCR 의 결과입니다 : Test1 Doc 및 Test2 Doc(Test1 Doc and Test2 Doc) .
ABBYY FineReader 온라인
FineReader Online 을 사용 하려면 계정에 등록해야 합니다. 이 계정을 사용하면 최대 10페이지의 OCR 을 15일 동안 무료로 사용할 수 있습니다. (OCR)몇 페이지에 대해 일회성 OCR 만 수행해야 하는 경우 이 서비스를 사용할 수 있습니다. 등록 후 확인 이메일(confirmation email) 에 있는 확인 링크(verify link) 를 클릭했는지 확인 하십시오.(Make)

상단의 인식(Recognize) 을 클릭 한 다음 업로드(Upload) 를 클릭하여 파일을 선택합니다. 언어, 출력 형식을 선택한 다음 하단의 인식 을 클릭합니다. (Recognize)이 사이트는 깨끗한 인터페이스와 광고도 없습니다.
내 테스트에서 이 사이트는 첫 번째 테스트 문서(test document) 에서 텍스트를 가져올 수 있었지만 Word 문서(Word doc) 를 열었을 때 크기가 정말 커서 결국 다시 작업을 수행하고 출력 형식으로 (output format)일반 텍스트(Plain Text) 를 선택했습니다 .
열이 있는 두 번째 테스트에서는 Word 문서(Word document) 가 비어 있었고 텍스트를 찾을 수조차 없었습니다. 그곳에서 무슨 일이 일어났는지 확실하지 않지만 간단한 단락 외에는 아무 것도 처리할 수 없는 것 같습니다. 다음은 FineReader 의 결과입니다 : Test1 Doc 및 Test2 Doc.
NewOCR
다음 사이트인 NewOCR.com 은 괜찮았지만 첫 번째 사이트만큼 좋지는 않았습니다. 첫째, 광고가 있지만 고맙게도 톤은 아닙니다. 먼저 파일을 선택한 다음 미리보기(Preview) 버튼을 클릭합니다.

그런 다음 이미지를 회전하고 텍스트를 스캔할 영역을 조정할 수 있습니다. 스캐너가 연결된 컴퓨터에서 스캔 프로세스(scanning process) 가 작동 하는 방식과 거의 비슷합니다 .

문서에 여러 열이 있는 경우 페이지 레이아웃 분석( Page layout analysis) 버튼 을 확인할 수 있으며 텍스트를 열로 분할하려고 합니다. OCR 버튼 을 (OCR button)클릭(Click) 하고 완료될 때까지 몇 초간 기다린 다음 페이지가 새로 고쳐지면 아래로 스크롤합니다.
첫 번째 테스트에서는 모든 텍스트를 올바르게 얻었지만 어떤 이유에서인지 문서의 모든 T를 대문자로 표시했습니다! 왜 그렇게 하는지는 모르겠지만 그렇게 했습니다. 페이지 분석(page analysis) 이 활성화 된 두 번째 테스트에서는 대부분의 텍스트를 얻었지만 레이아웃은 완전히 벗어났습니다.
다음은 NewOCR : Test1 Doc 및 Test2 Doc의 결과입니다.
결론
보시다시피, 무료는 불행히도 대부분의 경우 실제로 매우 좋은 결과를 제공하지 않습니다. 언급된 첫 번째 사이트는 모든 텍스트를 잘 인식할 뿐만 아니라 원본 문서의 형식을 유지하기 때문에 단연 최고입니다.
그러나 텍스트가 필요한 경우 위의 대부분의 웹 사이트에서 이를 수행할 수 있습니다. 질문이 있으시면 언제든지 댓글을 남겨주세요. 즐기다!
5 Free Online OCR Services Tested and Reviewed
Have a PDF document or an image that you would like to convert to text? Recently, someone sent me a document in the mail that I neеded to edit and send back wіth corrections. The person couldn’t locate a digitаl copy, so I was tasked with gеtting all that text into digital format.
There was no way I was going to spend hours typing everything back in, so I ended up taking a nice high-quality picture of the document and then burned my way through a bunch of online OCR services to see which one would give me the best results.
In this article, I’ll go through a couple of my favorite sites for OCR that are free. It’s worth noting that most of these sites provide a basic free service and then have paid options if you want extra features like bigger images, multi-page PDF documents, different input languages, etc.
It’s also good to know beforehand that most of these services will not be able to match the formatting of your original document. These are mainly for extracting text and that’s it. If you need everything to be in a specific layout or format, you’ll have to manually do that once you get all the text from the OCR.
In addition, the best results for getting the text will come from documents with a 200 to 400 DPI resolution. If you have a low DPI image, the results will not be as good.
Lastly, there were a lot of sites I tested that just didn’t work. If you Google free online OCR, you’ll see a bunch of sites but several of the sites in the top 10 results didn’t even complete the conversion. Some would time out, other would give errors and some just got stuck on the “converting” page, so I didn’t even bother to mention those sites.
For each site, I tested two documents to see how well the output would be. For my tests, I simply used my iPhone 5S to take a picture of both documents and then uploaded them directly to the websites for conversion.
In case you want to see what the images looked like that I used for my test, I have attached them here: Test1 and Test2. Note that these are not the full resolution versions of the images taken from the phone. I used the full resolution image when uploading to the sites.
OnlineOCR
OnlineOCR.net is a clean and simple site that delivered very good results in my test. The main thing I like about it is that it doesn’t have tons of ads all over the place, which is usually the case with these kinds of niche service sites.
To start, select your file and wait till it finishes uploading. The max upload size for this site is 100 MB. If you register for a free account, you get a few extra features like the bigger upload size, multi-page PDFs, different input languages, more conversions per hour, etc.
Next, choose your input language and then choose the output format. You can choose from Word, Excel, or Plain Text. Click the Convert button and you’ll see the text displayed at the bottom in a box along with a download link.
If all you want is the text, just copy and paste it from the box. However, I suggest you download the Word document because it does a surprisingly great job of keeping the layout of the original document.
For example, when I opened the Word document for my second test, I was surprised to find that the document included a table with three columns, just like in the image.
Out of all the sites, this one was the best by far. It’s totally worth registering for if you need to do a lot of conversions.
For completeness, I am also going to link to the output files created by each service so you can see the results for yourself. Here are the results from OnlineOCR: Test1 Doc and Test2 Doc.
Note that when opening these Word documents on your computer, you’ll get a message in Word stating that it’s from the Internet and editing has been disabled. That is perfectly OK because Word doesn’t trust documents from the Internet and you really do not have to enable editing if you just want to view the document.
i2OCR
Another site that gave pretty good results was i2OCR. The process is very similar: choose your language, file, and then press Extract Text.
You’ll have to wait a minute or two here because this site takes a bit longer. Also, in Step 2, make sure that your image is showing right-side up in the preview, otherwise you’ll get a bunch of gibberish as output. For some reason, the images from my iPhone were showing in portrait mode on my computer, but landscape when I uploaded to this site.
I had to manually open the image in a photo editing app, rotate it 90 degrees, then rotate it back to portrait and then save it again. Once complete, scroll down and it’ll show you a preview of the text along with a download button.
This site fared pretty well with the output for the first test, but didn’t do so well with the second test that had the column layout. Here are the results from i2OCR: Test1 Doc and Test2 Doc.
FreeOCR
Free-OCR.com will take your images and convert them into plain text. It does not have an option to export to Word format. Choose your file, select a language and then click Start.
The site is fast and you’ll get the output fairly quickly. Just click on the link to download the text file to your computer.
As with NewOCR mentioned down below, this site capitalizes all the T’s in the document. I have no idea why it would do that, but for some odd reason this site and NewOCR both did this. It’s not a big deal to change it, but it’s a tedious process you really shouldn’t have to do.
Here are the results from FreeOCR: Test1 Doc and Test2 Doc.
ABBYY FineReader Online
In order to use FineReader Online, you have to register for an account, which gets you a 15-day free trial to OCR up to 10 pages for free. If you only need to do a one-time OCR for a couple of pages, then you can use this service. Make sure that you click the verify link in the confirmation email after you register.
Click on Recognize at the top and then click Upload to select your file. Choose your language, output format and then click Recognize at the bottom. This site has a clean interface and no ads too.
In my tests, this site was able to grab the text from the first test document, but it was absolutely enormous when I opened the Word doc, so I ended up doing it again and choosing Plain Text as the output format.
For the second test with the columns, the Word document was empty and I couldn’t even find the text. Not sure what happened there, but it doesn’t seem to be able to handle anything other than simple paragraphs. Here are the results from FineReader: Test1 Doc and Test2 Doc.
NewOCR
The next site, NewOCR.com, was OK, but not nearly as good as the first site. Firstly, it’s got ads, but thankfully not a ton. You first select your file and then click the Preview button.
You can then rotate the image and adjust the area where you want to scan for text. It’s pretty much kind of like how the scanning process works on a computer with an attached scanner.
If the document has multiple columns, you can check the Page layout analysis button and it will try to split the text up into columns. Click the OCR button, wait a few seconds for it to complete and then scroll down to the bottom when the page refreshes.
In the first test, it got all the text correctly, but for some reason capitalized every T in the document! No idea why it would do that, but it did. In the second test with page analysis enabled, it got most of the text, but the layout was completely off.
Here are the results from NewOCR: Test1 Doc and Test2 Doc.
Conclusion
As you can see, free doesn’t really give you very good results most of the time unfortunately. The first site mentioned is the best by far because not only did it do a great job of recognizing all the text, it also managed to retain the format of the original document.
If you just need text, though, most of the websites above should be able to do that for you. If you have any questions, feel free to comment. Enjoy!

{kind=link}
{kind=link}