오프라인에서 볼 수 있도록 웹페이지나 웹사이트를 저장해야(Need to save a webpage or website so that you can view it offline) 합니까? 오랜 시간 동안 오프라인 상태지만 즐겨찾는 웹사이트를 탐색하고 싶으십니까? Firefox 를 사용하는 경우 문제를 해결할 수 있는 Firefox 추가 기능 이 하나 있습니다.
ScrapBook 은 웹 페이지(web page) 를 저장하고 관리하기 쉬운 방식으로 구성이 되는 멋진 Firefox 확장 프로그램 입니다. (Firefox extension)이 추가 기능의 정말 멋진 점은 매우 가볍고 빠르며 웹 페이지(web page) 의 로컬 복사본을 거의 완벽하게 정확하게 캐시하고 여러 언어를 지원한다는 것입니다. 많은 그래픽과 멋진 CSS 스타일로 여러 (CSS)웹 페이지(web page) 에서 테스트했으며 오프라인 버전이 온라인 버전과 정확히 동일하게 보이는 것을 보고 놀라울 정도로 기뻤습니다.
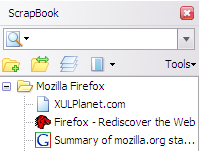
스크랩북(ScrapBook) 은 다음과 같은 용도로 사용할 수 있습니다 .
- 단일 웹 페이지 저장
- (Save snippet or portion)단일 웹 페이지 의 (Web page)스니펫 또는 일부 저장
- 전체 웹 사이트 저장
- 폴더, 하위 폴더가 있는 책갈피(Bookmarks) 와 동일한 방식으로 컬렉션 구성
- 전체 컬렉션의 전체 텍스트(Full text) 검색 및 빠른 필터링 검색
- 수집된 웹페이지 편집
- Text/HTML editOpera's Notes와 유사한 텍스트/HTML 편집 기능
스크랩북 설치
이 글을 쓰는 시점에서 v33인 최신 버전의 Firefox(Firefox) 를 실행하고 있다면 ScrapBook 을 제대로 사용할 수 있도록 일부 설정을 조정해야 합니다 . 기본적으로 ScrapBook 아이콘(ScrapBook icon) 은 어디에도 표시(t show) 되지 않으므로 웹 페이지를 마우스 오른쪽 버튼으로 클릭하는 경우에만 사용할 수 있습니다. 도구 모음의 아무 곳이나 마우스 오른쪽 버튼으로 클릭하고 사용자 지정(Customize) 을 선택하여 도구 모음이나 메뉴에 버튼을 추가합니다 .

사용자 정의 화면(Customize screen) 에서 왼쪽에 스크랩북 아이콘(ScrapBook icon) 이 표시 됩니다. 계속해서 상단의 도구 모음이나 메뉴로 드래그하십시오. 그런 다음 사용자 정의 종료(Exit Customize) 버튼을 클릭하십시오.

ScrapBook 을 사용하여 웹 사이트를 저장 하기 전에 추가 기능에 대한 설정을 변경할 수 있습니다. 오른쪽 상단 의 메뉴 버튼(menu button) (가로선 3개)을 클릭한 다음 추가 기능(Add-ons) 을 클릭하면 됩니다 .

이제 확장 을 클릭한 다음 (Extensions)스크랩북 애드온(ScrapBook add-on) 옆 에 있는 옵션(Options) 버튼을 클릭하십시오 .

여기에서 키보드 단축키, 데이터가 저장되는 위치 및 기타 사소한 설정을 변경할 수 있습니다.

스크랩북을 사용하여 사이트 다운로드
이제 실제로 프로그램을 사용하는 방법에 대해 자세히 알아보겠습니다. 먼저(First) 웹 페이지를 다운로드할 웹사이트를 로드합니다. 다운로드를 시작하는 가장 쉬운 방법은 페이지의 아무 곳이나 마우스 오른쪽 버튼으로 클릭 하고 메뉴 하단에서 페이지 저장(Save Page) 또는 다른 이름 으로 페이지 저장을 선택하는 것입니다. (Save Page As)이 두 가지 옵션은 ScrapBook 에 의해 추가됩니다 .

페이지 저장(Save Page) 을 사용하면 폴더를 선택한 다음 현재 페이지만 자동으로 저장할 수 있습니다. 내가 일반적으로 하는 더 많은 옵션을 원하면 다른 이름으로 페이지 저장(Save Page) 옵션을 클릭합니다. 많은 옵션 중에서 선택하고 선택할 수 있는 또 다른 대화 상자가 나타납니다.
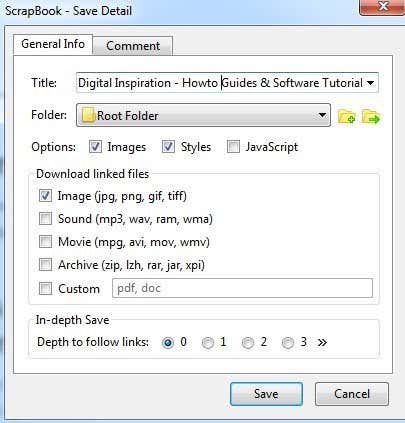
중요한 섹션은 옵션(Options) , 링크된 파일 다운로드(Download linked files) 섹션, 상세 저장(In-depth Save) 옵션입니다. 기본적으로 ScrapBook 은 이미지와 스타일을 다운로드하지만 웹사이트에서 JavaScript가 제대로 작동하도록 요구하는 경우 JavaScript 를 추가할 수 있습니다.(JavaScript)
링크 된 파일 다운로드(Download) 섹션은 링크된 이미지만 다운로드하지만 사운드, 동영상 파일, 아카이브 파일을 다운로드하거나 다운로드할 정확한 파일 유형을 지정할 수도 있습니다. 이것은 특정 유형의 파일( Word 문서(Word docs) , PDF(PDFs) 등)에 대한 많은 링크가 있는 웹 사이트에 있고 모든 관련 파일을 빠르게 다운로드하려는 경우에 정말 유용한 옵션입니다.
마지막으로, 심층 저장(In-depth Save) 옵션은 웹사이트의 더 많은 부분을 다운로드하는 방법입니다. 기본적으로 0으로 설정되어 있어 사이트의 다른 페이지로 연결되는 링크나 해당 문제에 대한 다른 링크를 따라가지 않습니다. 하나를 선택하면 현재 페이지와 해당 페이지에서 링크된 모든 항목을 다운로드합니다. (page and everything)Depth of 2는 현재 페이지, 첫 번째 링크 페이지 및 첫 번째 링크 페이지의 모든 링크에서도 다운로드됩니다.

(Click)저장 버튼 을 (Save button)클릭 하면 새 창이 열리고 페이지가 다운로드되기 시작합니다. 일시 중지(Pause) 버튼을 즉시 누르고 싶을 것 입니다. 이유를 알려드리겠습니다. ScrapBook 을 실행하기 만 하면 다른 사이트나 광고 네트워크로 연결될 수 있는 소스 코드(source code) 의 모든 항목을 포함하여 페이지에서 모든 것을 다운로드하기 시작합니다 . 위 이미지에서 볼 수 있듯이 메인 사이트(labnol.org) 외부에서 googleadservices.com(googleadservices.com and something) 에서 광고를 다운로드 하고 ctrlq.org에서 무언가를 다운로드하고 있습니다.
오프라인에서 탐색하는 동안 광고가 사이트에 표시되기를 정말로 원하십니까? 이것은 또한 많은 시간과 대역폭(time and bandwidth) 을 낭비 하므로 가장 좋은 방법은 Pause 를 누른 다음 Filter 버튼을 클릭하는 것입니다.

가장 좋은 두 가지 옵션은 Restrict to Domain 및 Restrict to Directory 입니다. 일반적으로 이들은 동일하지만 특정 사이트에서는 다릅니다. 원하는 페이지를 정확히 알고 있다면 문자열로 필터링하고 고유한 URL 을 입력할 수도 있습니다 . 이 옵션은 다른 모든 정크를 제거하고 소셜 미디어 사이트, 광고 네트워크 등이 아닌 실제 웹사이트에서 콘텐츠를 다운로드하기 때문에 훌륭합니다.
계속해서 시작(Start) 을 클릭 하면 페이지 다운로드가 시작됩니다. 다운로드 시간은 인터넷 연결(Internet connection) 속도와 다운로드하는 웹사이트의 정확한 양에 따라 달라집니다 . 추가 기능은 대부분의 사이트에서 훌륭하게 작동하며 내가 겪은 유일한 문제는 일부 사이트에서 자체 콘텐츠에 연결하는 데 사용하는 URL 이 절대 (URLs)URL(URLs) 이라는 것 입니다.
절대 URL(URLs) 의 문제는 오프라인 상태 에서 Firefox 에서 (Firefox)색인 페이지(index page) 를 열고 링크를 클릭하려고 하면 로컬 캐시가 아닌 실제 웹사이트에서 로드를 시도한다는 것입니다. 이러한 경우 다운로드 디렉토리(download directory) 를 수동으로 열고 페이지를 열어야 합니다. 고통스럽고 소수의 사이트에서만 발생했지만 발생합니다. 도구 모음 에서 스크랩북 버튼(ScrapBook button) 을 클릭한 다음 사이트를 마우스 오른쪽 버튼으로 클릭하고 도구(Tools) – 파일 표시 (Show Files)를 선택 하여 (site and choosing)다운로드 폴더(download folder) 를 볼 수 있습니다 .

탐색기에서 유형별(Type) 로 정렬한 다음 HTML 문서 (HTML Document. ) 라는 파일까지 아래로 스크롤합니다 . 콘텐츠 페이지는 일반적으로 index_00x 파일이 아니라 default_00x 파일입니다.

Firefox 를 사용하지 않고 웹 페이지를 컴퓨터에 다운로드하려는 경우 나중에 오프라인에서 검색 할 수 있도록 전체 웹 사이트(web site) 를 자동으로 다운로드하는 WinHTTrack 이라는 소프트웨어를 확인할 수도 있습니다. (WinHTTrack)(WinHTTrack)그러나 WinHTTrack 은 많은 양의 공간을 사용하므로 하드 드라이브에 충분한 여유 공간이 있는지 확인하십시오.
두 프로그램 모두 전체 웹 사이트를 다운로드하거나 단일 웹 페이지를 다운로드하는 데 적합합니다. 실제로는 WordPress 등과 같은 CMS 소프트웨어(CMS software) 에 의해 생성되는 링크의 수가 방대하기 때문에 전체 웹사이트를 다운로드하는 것은 거의 불가능 합니다. 질문이 있는 경우 댓글을 게시하세요. 즐기다!
Download Entire Web Sites in Firefox using ScrapBook
Need to save a webpage or website so that you can view it offline? Are you going to be offline for an extended period of time, but want to be able to browse through your favorite website? If you’re using Firefox, then there is one Firefox add-on that can solve your problem.
ScrapBook is an awesome Firefox extension that helps you to save web pages and organize them in a very easy to manage way. The really cool thing about this add-on is that it’s very light, speedy, accurately caches a local copy of a web page almost perfectly and supports multiple languages. I tested it out on several web pages with a lot of graphics and fancy CSS styles and was surprisingly happy to see that the offline version looked exactly the same as the online version.
You can use ScrapBook for the following purposes:
- Save a single Web page
- Save snippet or portion of a single Web page
- Save an entire Web site
- Organize the collection in the same way as Bookmarks with folders, sub-folders
- Full text search and fast filtering search of the entire collection
- Editing of the collected Web page
- Text/HTML edit feature resembling Opera’s Notes
Installing ScrapBook
If you’re running the latest version of Firefox, which is v33 for me as of this writing, you’ll have to adjust some settings so that you can use ScrapBook properly. By default, the ScrapBook icon won’t show up anywhere, so the only way you can use it is if you right-click on a webpage. Add the button to your toolbar or to the menu by right clicking anywhere on the toolbar and choose Customize.
On the Customize screen, you’ll see the ScrapBook icon on the left-hand side. Go ahead and drag that to either the toolbar at the top or to the menu. Then go ahead and click on the Exit Customize button.
Before we get into using ScrapBook to save a website, you might want to change the settings for the add-on. You can do that by clicking on the menu button at the top right (three horizontal lines) and then clicking on Add-ons.
Now click on Extensions and then click on the Options button next to the ScrapBook add-on.
Here you can change the keyboard shortcuts, the location where the data is stored and other minor settings.
Using ScrapBook to Download Sites
Now let’s get into the details of actually using the program. First, load the website you want to download web pages for. The easiest way to start a download is to right-click anywhere on the page and choose either Save Page or Save Page As towards the bottom of the menu. These two options are added by ScrapBook.
Save Page will let you choose a folder and then automatically save the current page only. If you want more options, which I normally do, then click on the Save Page As option. You’ll get another dialog where you can pick and choose from a whole lot of options.
The important sections are the Options, Download linked files section, and then In-depth Save options. By default, ScrapBook will download images and styles, but you can add JavaScript if a website requires that to work properly.
The Download linked files section will just download linked images, but you can also download sounds, movie files, archive files or specify the exact type of files to download. This is a really useful option if you are on a website that has a bunch of links to a certain type of file (Word docs, PDFs, etc) and you want to download all the associated files quickly.
Lastly, the In-depth Save option is how you would go about download larger portions of a website. By default, it’s set to 0, which means it won’t follow any links to other pages on the site or any other link for that matter. If you choose one, it will download the current page and everything that is linked from that page. Depth of 2 will download from the current page, the 1st linked page and any links from the 1st linked page also.
Click the Save button and new window will pop up and the pages will begin to download. You’ll want to press the Pause button immediately and let me tell you why. If you just let ScrapBook run, it will start to download everything from the page, including all the stuff in the source code that may link to a bunch of other sites or ad networks. As you can see in the image above, outside of the main site (labnol.org), it’s downloading ads from googleadservices.com and something from ctrlq.org.
Do you really wants the ads to show up on the site while you’re browsing it offline? This will also waste a lot of time and bandwidth, so the best thing to do is to press Pause and then click on the Filter button.
The best two options are Restrict to Domain and Restrict to Directory. Normally these are the same, but on certain sites they will be different. If you know exactly what pages you want, you can even filter by string and type in your own URL. This option is fabulous because it gets rid of all the other junk and only downloads content from the actual website you’re on rather than from social media sites, ad networks, etc.
Go ahead and click Start and the pages will start to download. The time to download will depending on your Internet connection speed and exactly how much on the website you are downloading. The add-on works great for most sites and the only issue that I have run into is that on some sites, the URLs they use for linking to their own content are absolute URLs.
The problem with absolute URLs is that when you open the index page in Firefox while offline and try to click on any of the links, it will try to load from the actual website rather than from the local cache. In those cases, you have to manually open the download directory and open the pages. It’s a pain and I’ve only had it happen on a handful of sites, but it does occur. You can view the download folder by clicking on the ScrapBook button on your toolbar and then right clicking on the site and choosing Tools – Show Files.
In Explorer, sort by Type and then scroll down to the files called HTML Document. The content pages are normally the default_00x files, not the index_00x files.
If you’re not using Firefox and still want to download webpages to your computer, you can also check out a software called WinHTTrack that will automatically download an entire web site for later browsing offline. However, WinHTTrack uses up a good amount of space, so make sure you have enough free space on your hard drive.
Both programs works well for downloading entire websites or for downloading single webpages. In practice, downloading an entire website is almost impossible because of the massive number of links that are generated by CMS software like WordPress, etc. If you have any questions, post a comment. Enjoy!
